依旧是一切之前
距离上一次更新已经是太久了,中间也想过更新一些比如在之前公司自己写的日志工具如何做到用了反射也很快,想过写如何压测分析然后让接口RT降低接近40%等等什么的,甚至想过出一篇阿卡丽如何单杀大师青钢影的教学,但是想着也没太大技术含量,不好意思献丑(且有点懒),就一直建了目录就不了了之。这几天一想,已经是要成为了这么久的社畜了,再不记录一下足迹,22年上半年就要过去了。。刚好有个东西稍微值得写写,那就记一下吧,同时,也希望上海早点解封,这样也好吃到宇哥的散伙饭。(当然,裕兴记和老乡鸡就算了
机器再见,full gc你好
最近一年来经济属实不太行,公司也要求降本增效,原来有一堆冗余机器的服务需要一减再减,因此原来因为机器多而隐藏的问题就逐渐浮现了出来。。比如以前服务的单机QPS上限预估为2000+,而如今需要承载3000+,因为单机流量的上涨,内存再也不等待每日凌晨x点的主动gc,直接就在下午纷纷开始跳水,属实影响服务性能。又如每天的流量高峰期时,一些弹性机器刚刚出来,便"出道即巅峰",直接开始走向full gc的不归路。
如何让机器即可以尽可能承载更多的流量,又不会每天有额外的full gc,这是一个急需解决的问题。
问题分析
线上基本配置
简要说下基本情况,服务单机是日常单机平均2500QPS左右,周内峰值在3200QPS左右,内存占用速度与流量大小承正相关。
服务使用jdk8,机器内存为8G,jvm参数为(只展示这里较为需要的几个,例如CICompilerCount等不予展示):
1 | -Xms4096m -Xmx4096m -Xmn2g -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m XX:CMSInitiatingOccupancyFraction=70 |
易知堆内存为4G,其中新生代占2G,老年代占2G。而非一般的老比新为3:1的关系,这也彰显着服务可能流量稍高一点。当然,从此我们也能简单退出以下几点:
- eden区占1.6G,两个survivor区分别200MB左右;
- 老年代占用到1.4G时会触发full gc。
线上场景分析
说完了配置,来看看线上机器的新生代,老年代以及survivor区的一般时期的运行情况(模拟版)。
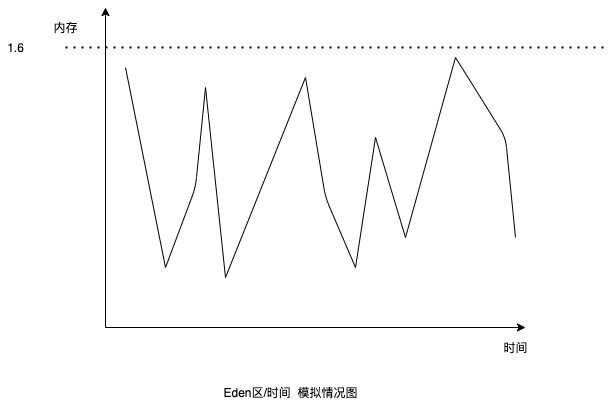
首先是Eden区,因为服务流量比较大,所以这小小的一个多G的内存不一会儿就会被占满,然后触发minor gc。时间上来看每隔1-2min就会触发一次,看起来虽是蛮频繁的,但是gc时间也都在100ms左右,对吞吐量无大影响。除此之外,并没有什么问题。
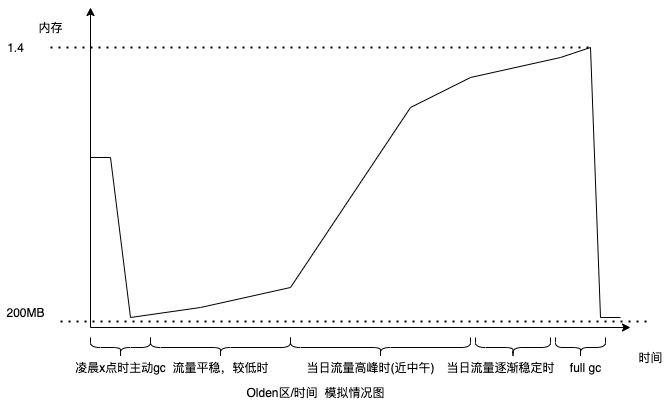
然后是老年代,看起来老年代确实是随着时间慢慢被填满的,没有什么突然的某一次minor gc前后的猛然提高,说明排除大对象什么的影响。此外,主动gc 以及 额外的full gc之后,老年代的所占内存极速下降到了200MB - 300MB 左右,也不存在大量对象清理不掉的情况。那是不是很多对象就应该在minor gc就被干掉才对呢?
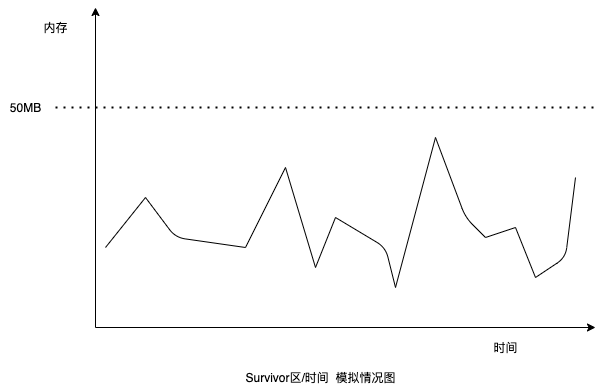
最后再来看看survivor区,看着波动并不是特别的明显,随着每次minor gc,确实内存占用是有下降的,每次晋升点到老年代倒也正常。
但是!!这survivor区可是每个分配了200MB左右,你一个survivor区一直占用才在50MB下波动是不是太过分了呢?二话不说,直接上机器把gc日志搞下来看看minor gc前对象晋升年龄分布,结果发现确实有点东西。。。
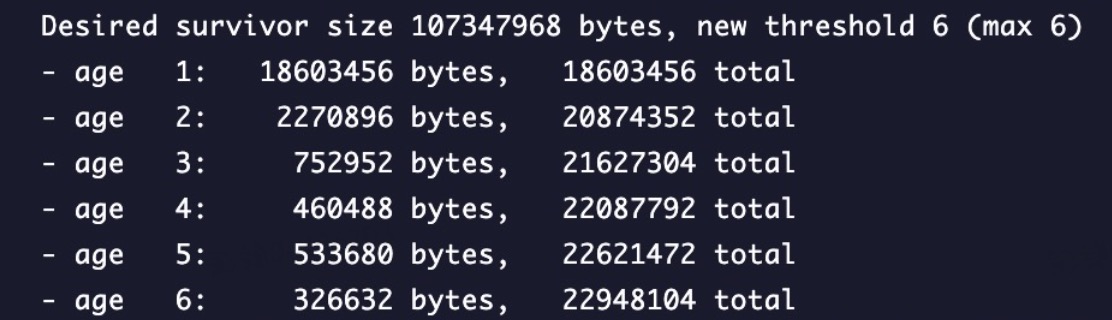
因为大多都差不多一样数据,那么久截取其中一个简单解读下,就是说
- 当前的晋升年龄是6,即这一次gc会把年龄为6的对象扔进老年代;
- survivor区当对象 <= 某个年龄段n的对象 大于 107MB时,会修改晋升阈值为n;当然这里的desired是通过
-XX:+printTenuringDestribution可以改的,但是一般都使用的默认的50,因此这里就是100MB左右(意为回收后希望survivor区就一直这个比例); - 当前survivor区对象占用内存之和不足 23MB;
其实我们只要看过一些相关的理论书籍(比如《深入理解Java虚拟机》),那么看到这里通常会有两个疑问:
- 为什么max 为 6 而不是 15?(书中说过默认晋升年龄是15)
- 不是说jvm能动态计算晋升年龄吗,为何总是和6一样?
为什么max 为 6 而不是 15?
这里可以参考Oracle的官网参数说明:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html ,直接搜-XX:MaxTenuringThreshold=threshold,可以看到这么一句话:
Sets the maximum tenuring threshold for use in adaptive GC sizing. The largest value is 15. The default value is 15 for the parallel (throughput) collector, and 6 for the CMS collector.
于是破案了,咱只是最大能设置为15,具体默认多少还得取决于用了什么垃圾收集器,这里我们用的CMS,因此就是6。。。那么根据前面的情况分析,full gc中很多对象还是应该可以在minor gc时候干掉才对,加上日志看出jvm的动态计算阈值就"几乎"没小于过6(注意是几乎,这里引出另外的问题) 以及 survivor区利用率就20%左右,因此我们完全可以提升一些晋升年龄阈值。
为何jvm动态计算出的晋升年龄总是和6一样?
我们都知道jvm是有动态计算晋升年龄的逻辑的,那么为什么明显6已经是不太合理的情况下,图中还是显示 "new threshold 6"呢?
我们可以看下jvm中关于这里的关键代码(注:survivor_capacity默认是50)
1 | uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) { |
计算动态晋升年龄阈值n的逻辑其实很简单,不多赘述了。
直接看最后一行,我们计算得到一个动态年龄age,然后和我们设置的阈值进行比较,两者取一个较小值。那么其实我们设置一个正常的阈值,则jvm计算的动态年龄age肯定一般比6大的,但是这里计算出来的age则基本是7了,那么new threshold 长期为 6 也就不足为奇了。
问题处理与预告
知道了问题所在,本着不改太多也能work的原则,我对晋升年龄进行了手动指定,这样保证其在高峰期也是能让老年代以较低水平上升;
我在线上灰度了一台机器,效果十分OK,类似下图:
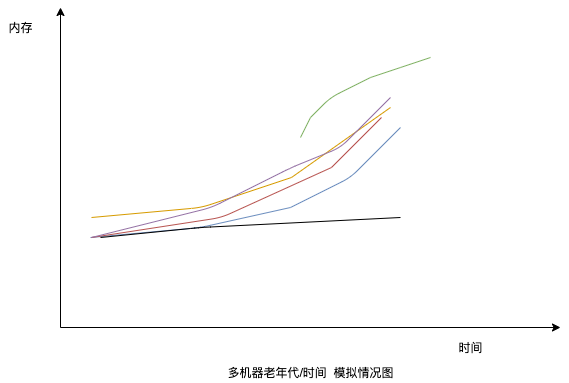
有没有一种万马奔腾,我自佁然不动的快感呢hhh。那么是否还可以爆改,比如进一步降低老年代空间什么的呢,我想当然是可以的,但是必要性不大,因为目前这个minor gc的耗时就很好,不是很高,毕竟过早优化是万恶之源。
诶等下,为何在大家都在奔向full gc时候,有一匹黑🐴(实则为绿线)突然凭空杀出,而且迅速赶超第一名,率先会发起full gc呢?
仔细一看,原来是因为流量上涨被自动扩容出来的弹性机器呀,话说按照常理来看服务启动后老年代不就300MB左右吗,为什么这一出来就800MB左右了呢,这不是"出道即巅峰"了吗?
难道真的是弹性机器弱于"人",下一篇博客里直接为其平反!
说明一下首先我是1. 两个问题都解决了再灰度的, 2. 不全是因为懒而分两篇,也因为这确实是两个问题,有一种递进感hh;另外,只能说,对"出道即巅峰"的排查和修复更有意思(
估计也要写更多)。。。