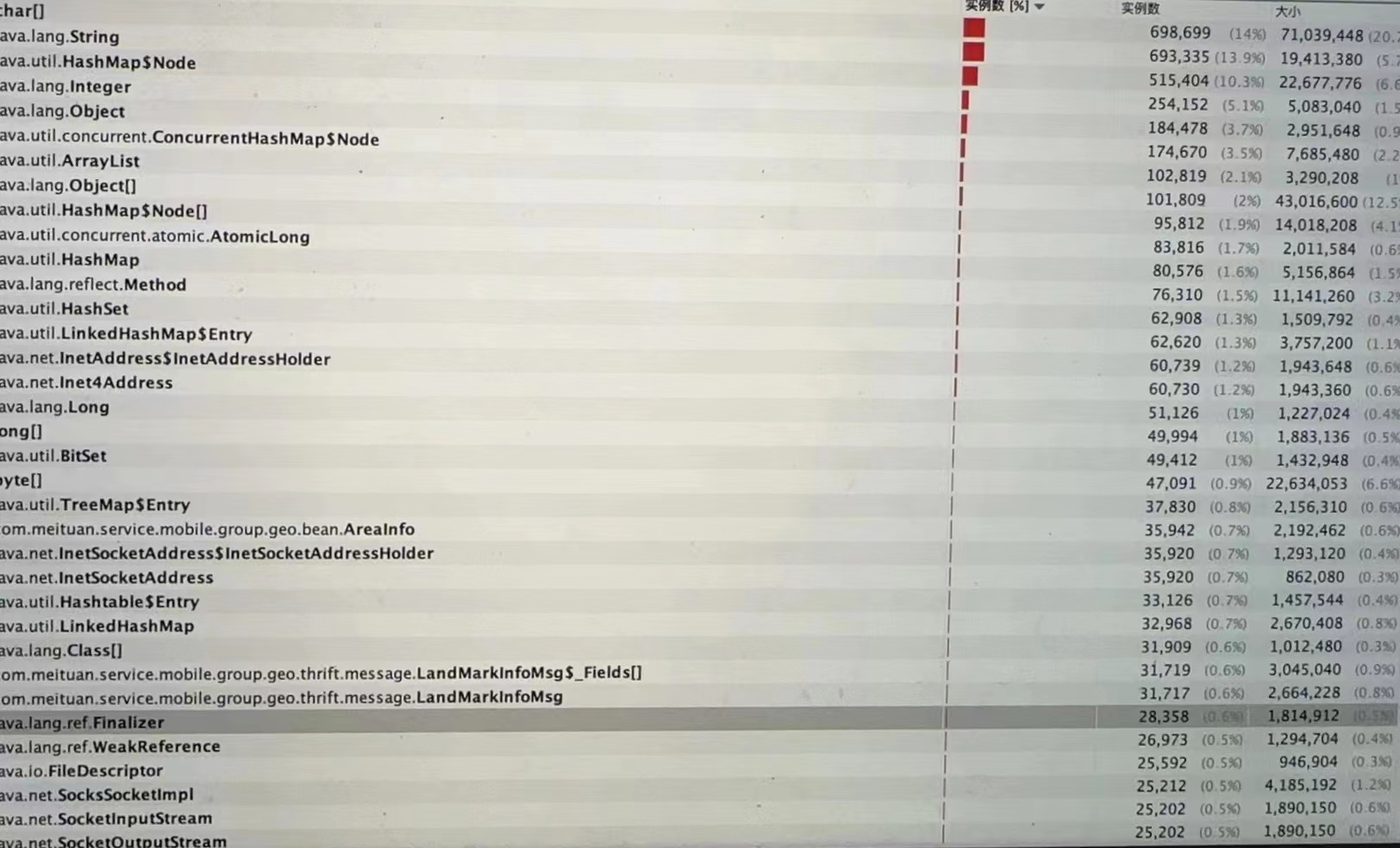
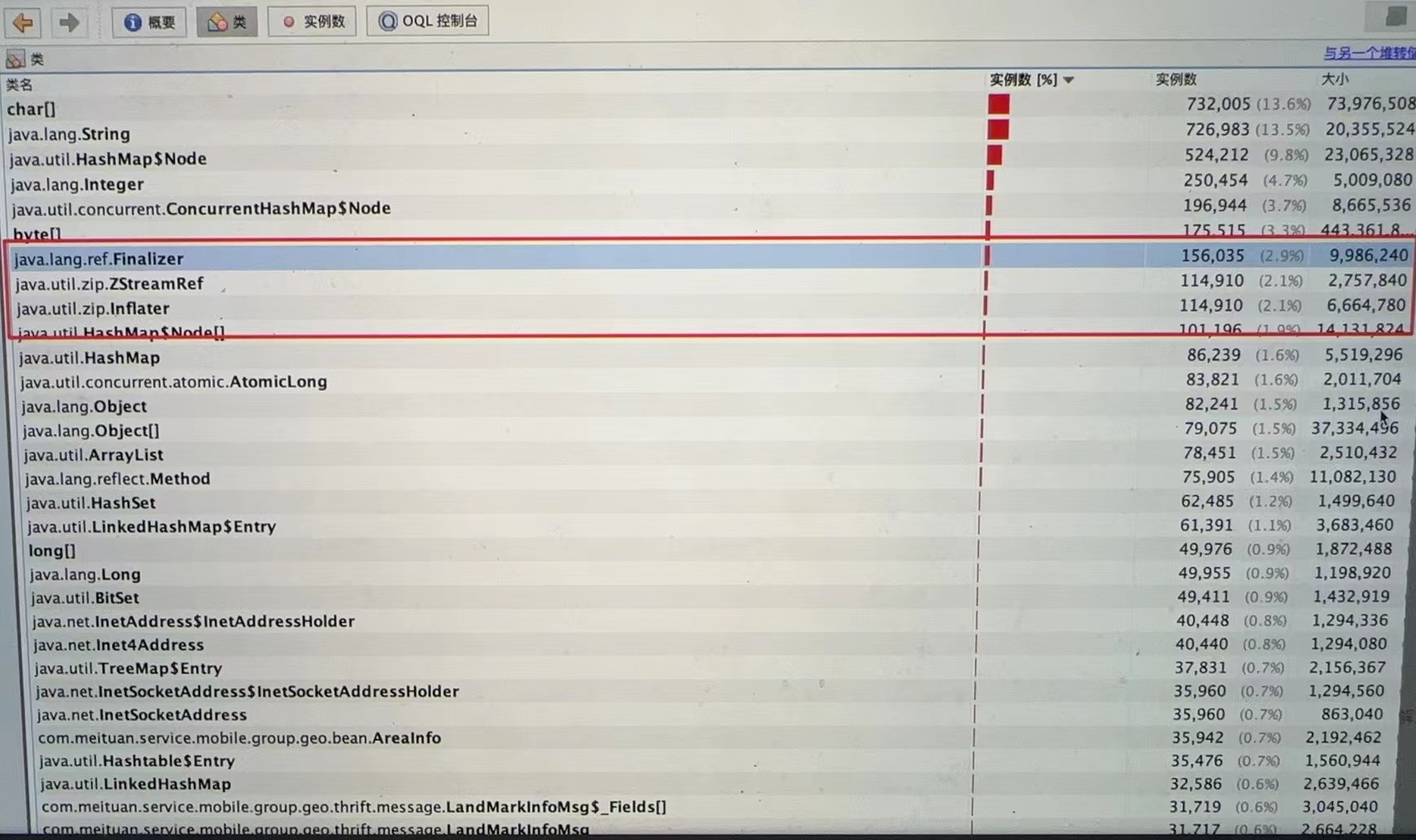
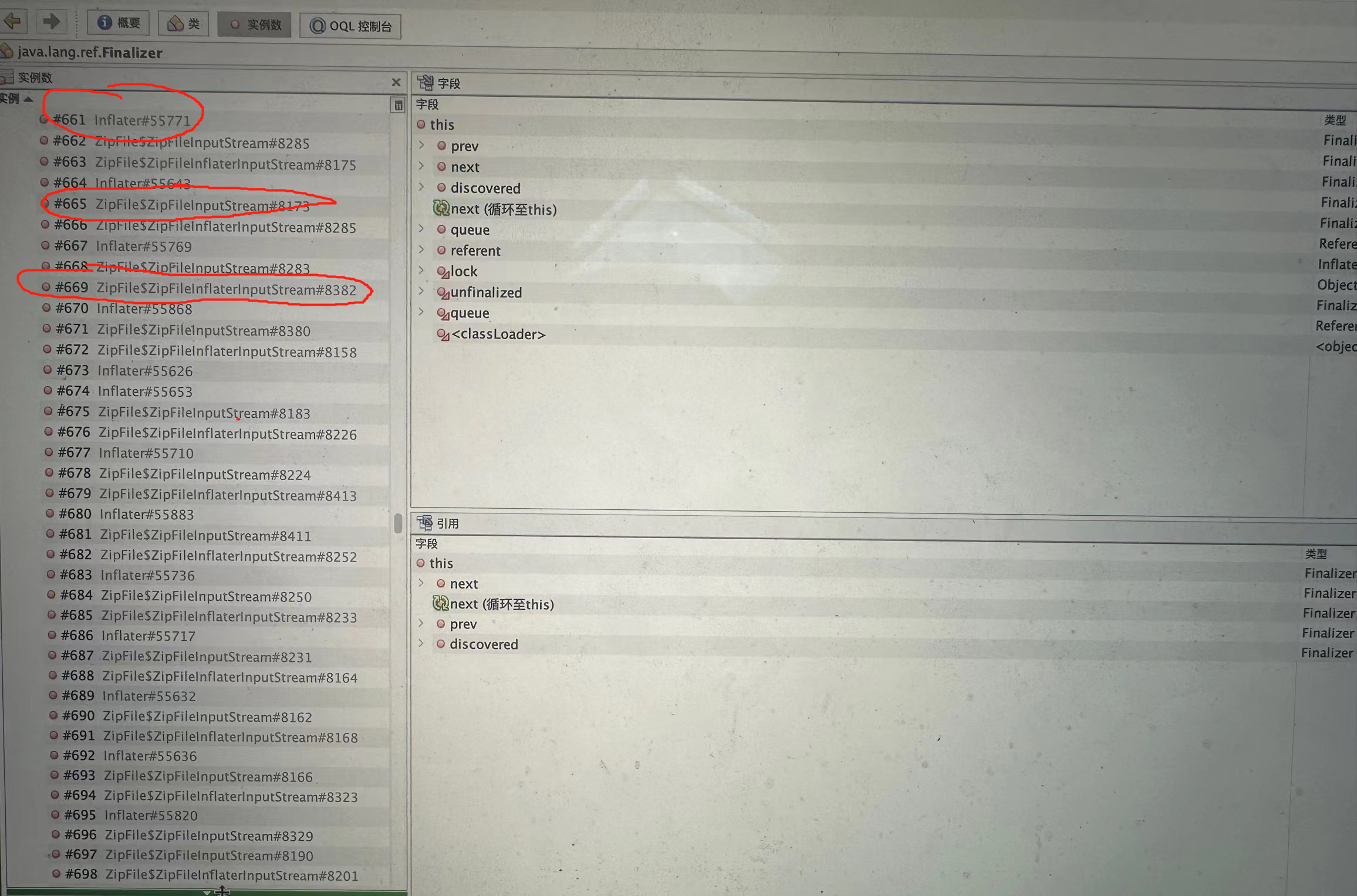
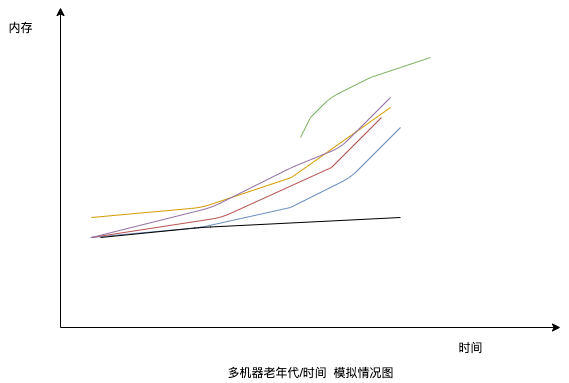由注释等可知ZipFile(This class is used to read entries from a zip file.) 以及 Inlater(This class provides support for general purpose decompression using the popular ZLIB compression library.)用处主要在于去解压文件信息。(且在gc后几乎无上方所提及得zip相关内容)
/******** AnnotationConfiguration ********/ @Override publicvoidconfigure(WebAppContext context)throws Exception { // 省略 // 顾名思义,此处为扫所有的注解 if (!_discoverableAnnotationHandlers.isEmpty() || _classInheritanceHandler != null || !_containerInitializerAnnotationHandlers.isEmpty()) scanForAnnotations(context); // 省略 } /** * Perform scanning of classes for discoverable * annotations such as WebServlet/WebFilter/WebListener * * @param context the context for the scan * @throws Exception if unable to scan */ protectedvoidscanForAnnotations(WebAppContext context) throws Exception { // JAVA版本相关,省略 // 日志打印,省略 //scan selected jars on the container classpath first parseContainerPath(context, parser); //email from Rajiv Mordani jsrs 315 7 April 2010 // If there is a <others/> then the ordering should be // WEB-INF/classes the order of the declared elements + others. // In case there is no others then it is // WEB-INF/classes + order of the elements. parseWebInfClasses(context, parser); //scan non-excluded, non medatadata-complete jars in web-inf lib parseWebInfLib(context, parser); //execute scan, either effectively synchronously (1 thread only), or asynchronously (limited by number of processors available) final Semaphore task_limit = (isUseMultiThreading(context) ? new Semaphore(ProcessorUtils.availableProcessors()) : new Semaphore(1)); final CountDownLatch latch = new CountDownLatch(_parserTasks.size()); final MultiException me = new MultiException(); for (final ParserTask p : _parserTasks) { task_limit.acquire(); context.getServer().getThreadPool().execute(new Runnable() { @Override publicvoidrun() { try { p.call(); } catch (Exception e) { me.add(e); } finally { task_limit.release(); latch.countDown(); } } }); } // ... }
/** * Scan jars in WEB-INF/lib. Only jars selected by MetaInfConfiguration, and that are not excluded by an ordering will be considered. */ publicvoidparseWebInfLib(final WebAppContext context, final AnnotationParser parser)throws Exception { List<Resource> jars = context.getMetaData().getWebInfResources(context.getMetaData().isOrdered()); for (Resource r : jars) { //for each jar, we decide which set of annotations we need to parse for final Set<Handler> handlers = new HashSet<Handler>(); FragmentDescriptor f = context.getMetaData().getFragmentDescriptorForJar(r); //if its from a fragment jar that is metadata complete, we should skip scanning for @webservlet etc // but yet we still need to do the scanning for the classes on behalf of the servletcontainerinitializers //if a jar has no web-fragment.xml we scan it (because it is not excluded by the ordering) //or if it has a fragment we scan it if it is not metadata complete if (f == null || !WebDescriptor.isMetaDataComplete(f) || _classInheritanceHandler != null || !_containerInitializerAnnotationHandlers.isEmpty()) { //register the classinheritance handler if there is one if (_classInheritanceHandler != null) handlers.add(_classInheritanceHandler); //register the handlers for the @HandlesTypes values that are themselves annotations if there are any handlers.addAll(_containerInitializerAnnotationHandlers); //only register the discoverable annotation handlers if this fragment is not metadata complete, or has no fragment descriptor if (f == null || !WebDescriptor.isMetaDataComplete(f)) handlers.addAll(_discoverableAnnotationHandlers); if (_parserTasks != null) { // 注:都是这个task,说明内部parse逻辑还有区别 ParserTask task = new ParserTask(parser, handlers, r); _parserTasks.add(task); } } } }
/******** AnnotationParser ********/ /** * Parse a single entry in a jar file * @param handlers the handlers to look for classes in * @param entry the entry in the potentially MultiRelease jar resource to parse * @param jar the jar file * @throws Exception if unable to parse */ protectedvoidparseJarEntry(Set<? extends Handler> handlers, Resource jar, MultiReleaseJarFile.VersionedJarEntry entry) throws Exception { if (jar == null || entry == null) return; //skip directories if (entry.isDirectory()) return;
String name = entry.getName(); //check file is a valid class file name if (isValidClassFileName(name) && isValidClassFilePath(name)) { String shortName = StringUtil.replace(name, '/', '.').substring(0, name.length() - 6); // 资源组装 addParsedClass(shortName, Resource.newResource("jar:" + jar.getURI() + "!/" + entry.getNameInJar())); if (LOG.isDebugEnabled()) LOG.debug("Scanning class from jar {}!/{}", jar, entry); try (InputStream is = entry.getInputStream()) { // 前面有出现过。asm解析类文件 scanClass(handlers, jar, is); } } } /******** Resource ********/ publicstatic Resource newResource(URL url) { return newResource(url, __defaultUseCaches); } /** * Construct a resource from a url. * @param url the url for which to make the resource * @param useCaches true enables URLConnection caching if applicable to the type of resource * @return a new resource from the given URL */ static Resource newResource(URL url, boolean useCaches) { if (url == null) returnnull; String urlString = url.toExternalForm(); // context启动该时扫描加过file if (urlString.startsWith("file:")) { try { returnnew PathResource(url); } catch (Exception e) { if (LOG.isDebugEnabled()) LOG.warn("Bad PathResource: {}", url, e); else LOG.warn("Bad PathResource: {} {}", url, e.toString()); returnnew BadResource(url, e.toString()); } } // 明显走的这个分支,在前面parseJarEntry方法中又加了一次前缀 // jar包中的class文件~ elseif (urlString.startsWith("jar:file:")) { returnnew JarFileResource(url, useCaches); } // 纯jar包 elseif (urlString.startsWith("jar:")) { returnnew JarResource(url, useCaches); }